
Atlassian | 2023-2025
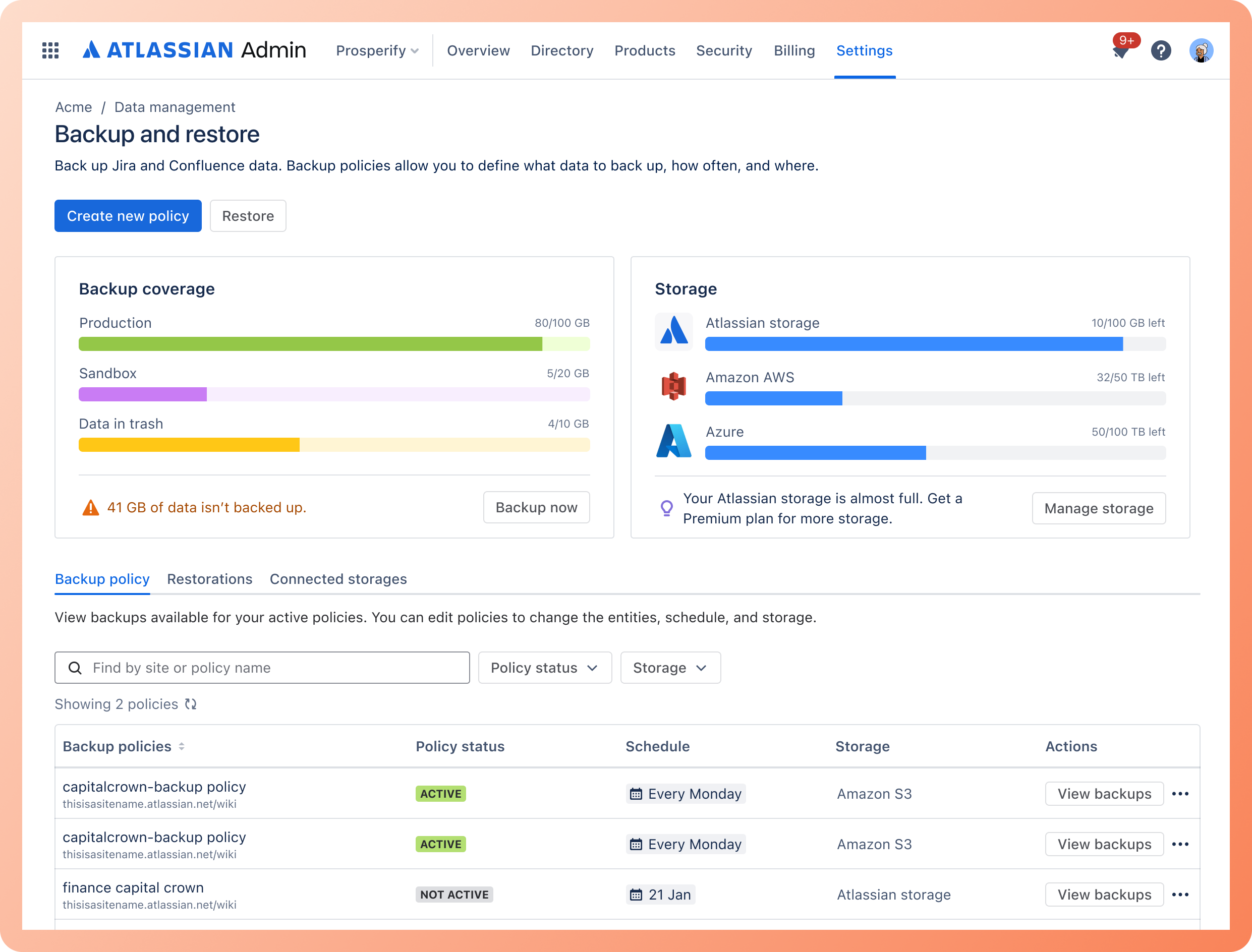
Backup and restore
Backup & Restore is a system-critical experience that enables cloud admins to safely create, monitor, and restore backups across large, data-heavy cloud sites.
Scope
Multi-year 0→1 foundation setup 1→2 system-scale expansion with advanced features
Focus areas
Backup creation, restore clarity, scheduling, external storage, reliability
My role
End-to-end UX ownership, cross-functional alignment, led design team of 4

1M+
customers unblocked
84%
adoption rate
3.3
SEQ benchmark
6.2
latest SEQ

Problem
Cloud admins need reliable backups to protect against deletion, corruption, ransomware, and failures — while also meeting strict compliance and audit requirements. But the existing system was support-driven, opaque, and unpredictable, leaving customers without confidence or control.
The challenge: A multi-year 0→1 and 1→2 effort requiring deep cross-functional alignment to redesign a mission-critical system, balancing architectural constraints, large-scale data behaviors, compliance needs, and long-running workflows while creating a simple, predictable experience for admins.
System constraints and complexity
This project required navigating deep technical and organizational constraints:

Compliance & retention rules
Strict data protection, retention, and audit standards shaped backup and restore behavior.

High-risk restore operations
Restores can overwrite production data, requiring protective safeguards and predictable behavior.

Multi-product dependencies
Backup behavior had to stay consistent across Jira, Confluence, and other cloud products.
Information architecture & policy lifecycle (IA / lifecyle map
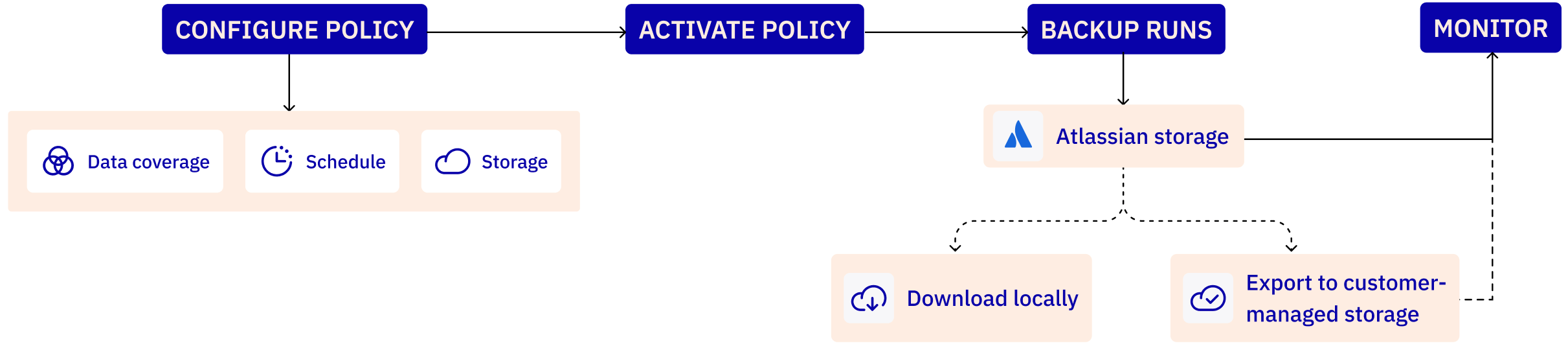
The original experience had fragmented entry points and unclear terminology, making it hard for admins to understand where backups lived or how scheduling and retention worked.
What I solved
- Mapped all admin entry points across Jira and Confluence
- Explored multiple IA models and aligned teams on a unified structure
- Introduced Backup Policies as the single source of truth for schedules, retention, and storage
- Defined a predictable lifecycle from scheduling → processing → storage → verification → retention → restore
Impact
A clear, scalable IA that reduced confusion, unified product behavior, and formed the foundation for all 1→2 improvements and future roadmap work.
Information architecture & policy lifecycle (IA / lifecyle map
Restores overwrite live data, and admins previously had no visibility into conflicts or what would change.
What I solved
- Worked with architects and backend teams to define predictable conflict rules
- Explored overwrite/merge models and aligned on a scalable approach
- Designed a Restore Preview showing what will be restored, overwritten, or skipped
- Added clear warnings and conflict summaries to reduce risky restores
Impact
Made high-risk restore operations transparent and predictable, reducing restore errors, support escalations, and admin anxiety.
Information architecture & policy lifecycle (IA / lifecyle map
Backup storage was the foundational architectural decision that shaped the entire roadmap. There were several viable ways to build this system, each with different implications for compliance, reliability, cost, performance, engineering effort, and enterprise expectations. Aligning on the right long-term model was critical to giving engineering a stable foundation for 0→1 and future scalability.
To drive alignment across teams with competing priorities, I led a series of structured cross-functional workshops with engineering architects, PMs, compliance, and platform teams to:
- Explore multiple conceptual models for how backups could be stored and accessed
- Map technical constraints against enterprise expectations
- Conduct tradeoff analysis across complexity, extensibility, security, and effort
- Align on a prioritized path that balanced present reality with long-term vision
This process led to three extensible storage models that support a wide range of enterprise needs while keeping the system maintainable and scalable.

01
Low visibility = Low confidence
Admins couldn’t see the job progress or verify outcomes, leading to uncertainty about backup success & system reliability.
trust issue

02
UNCLEAR SCHEDULING
Ambiguous timing and retention policies led to configuration errors and mistrust in the backup system's behavior.
reliability risk

03
Anxiety during restore
No conflict clarity caused fear of overwriting live data, making admins hesitant to perform critical restore operations.
adoption blocker

04
Storage Control Needed
Enterprises wanted the ability to store backups in their own S3 buckets for compliance and data sovereignty requirements.
enterprise requirement
Information architecture & policy lifecycle (IA / lifecyle map
Backup storage was the foundational architectural decision that shaped the entire roadmap. There were several viable ways to build this system, each with different implications for compliance, reliability, cost, performance, engineering effort, and enterprise expectations. Aligning on the right long-term model was critical to giving engineering a stable foundation for 0→1 and future scalability.
To drive alignment across teams with competing priorities, I led a series of structured cross-functional workshops with engineering architects, PMs, compliance, and platform teams to:
- Explore multiple conceptual models for how backups could be stored and accessed
- Map technical constraints against enterprise expectations
- Conduct tradeoff analysis across complexity, extensibility, security, and effort
- Align on a prioritized path that balanced present reality with long-term vision
This process led to three extensible storage models that support a wide range of enterprise needs while keeping the system maintainable and scalable.
I led the end-to-end UX direction, guided the design team, and aligned PM + engineering on priorities as we evolved from an API-only solution to a scalable Out-of-box Backup & restore experience.
0 → 1 foundation (From no UI → first usable product)
- Introduced the first self-serve UI for creating and downloading backups
- Transitioned from API-only + Marketplace partner tools to a built-in admin experience
- Added basic policy creation and manual downloadable backups
- Unblocked key enterprise customers who previously relied entirely on support
- Early SEQ benchmarking revealed significant usability gaps (avg 3.4 SEQ)
I led the end-to-end UX direction, guided the design team, and aligned PM + engineering on priorities as we evolved from an API-only solution to a scalable Out-of-box Backup & restore experience.
0 → 1 foundation (From no UI → first usable product)
- Introduced the first self-serve UI for creating and downloading backups
- Transitioned from API-only + Marketplace partner tools to a built-in admin experience
- Added basic policy creation and manual downloadable backups
- Unblocked key enterprise customers who previously relied entirely on support
- Early SEQ benchmarking revealed significant usability gaps (avg 3.4 SEQ)
Measured Improvement
- SEQ improved from 3.4 → 6.2 across core tasks
- Major improvements in:
- Policy creation
- Policy editing
- Restore flows
- Reduced ambiguity and error-prone steps across backup & restore workflows

Atlassian | 2023-2025
Backup and restore
Backup & Restore is a system-critical experience that enables cloud admins to safely create, monitor, and restore backups across large, data-heavy cloud sites.
Scope
Multi-year 0→1 foundation setup 1→2 system-scale expansion with advanced features
Focus areas
Backup creation, restore clarity, scheduling, external storage, reliability
My role
End-to-end UX ownership, cross-functional alignment, led design team of 4
1M+
customers unblocked
84%
adoption rate
3.3
SEQ benchmark
6.2
latest SEQ

Problem
Cloud admins need reliable backups to protect against deletion, corruption, ransomware, and failures — while also meeting strict compliance and audit requirements. But the existing system was support-driven, opaque, and unpredictable, leaving customers without confidence or control.
The challenge: A multi-year 0→1 and 1→2 effort requiring deep cross-functional alignment to redesign a mission-critical system, balancing architectural constraints, large-scale data behaviors, compliance needs, and long-running workflows while creating a simple, predictable experience for admins.
System constraints and complexity
This project required navigating deep technical and organizational constraints:
Compliance & retention rules
Strict data protection, retention, and audit standards shaped backup and restore behavior.
High-risk restore operations
Restores can overwrite production data, requiring protective safeguards and predictable behavior.
Multi-product dependencies
Backup behavior had to stay consistent across Jira, Confluence, and other cloud products.

Data scale & job duration
Large enterprise sites produced long-running, failure-prone jobs requiring resilient orchestration
Architecture alignment & storage models
Backup storage was the foundational architectural decision that shaped the entire roadmap. There were several viable ways to build this system, each with different implications for compliance, reliability, cost, performance, engineering effort, and enterprise expectations. Aligning on the right long-term model was critical to giving engineering a stable foundation for 0→1 and future scalability.
To drive alignment across teams with competing priorities, I led a series of structured cross-functional workshops with engineering architects, PMs, compliance, and platform teams to:
- Explore multiple conceptual models for how backups could be stored and accessed
- Map constraints against enterprise expectations
- Conduct tradeoff analysis across complexity, extensibility, security, and effort
- Align on a prioritized path that balanced present reality with long-term vision

Information architecture & policy lifecycle (IA / lifecycle map with simple overlay)
The original experience had fragmented entry points and unclear terminology, making it hard for admins to understand where backups lived or how scheduling and retention worked.
What I solved
- Mapped all admin entry points across Jira and Confluence
- Explored multiple IA models and aligned teams on a unified structure
- Introduced Backup Policies as the single source of truth for schedules, retention, and storage
- Defined a predictable lifecycle from scheduling → processing → storage → verification → retention → restore
Impact
A clear, scalable IA that reduced confusion, unified product behavior, and formed the foundation for all 1→2 improvements and future roadmap work.
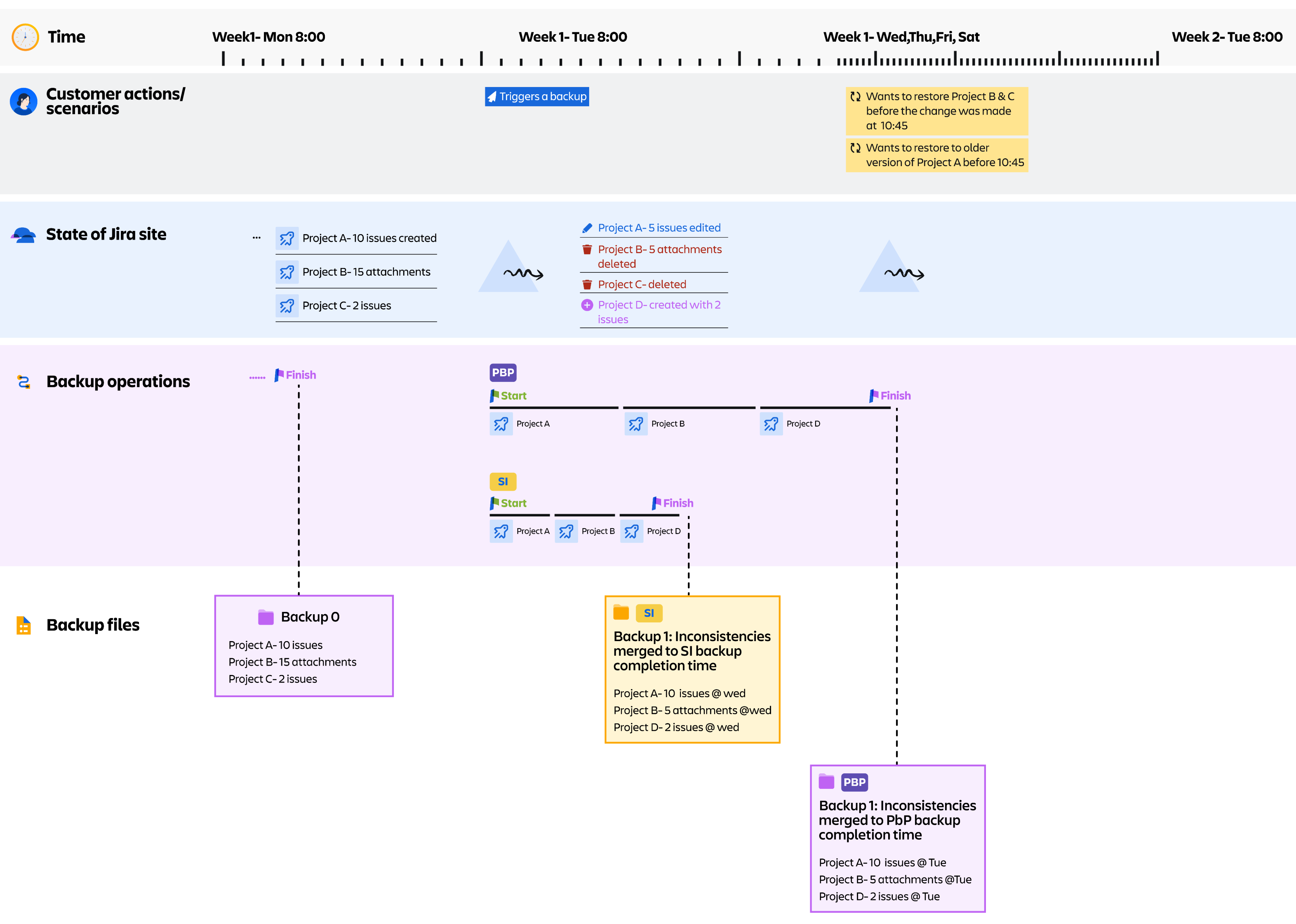
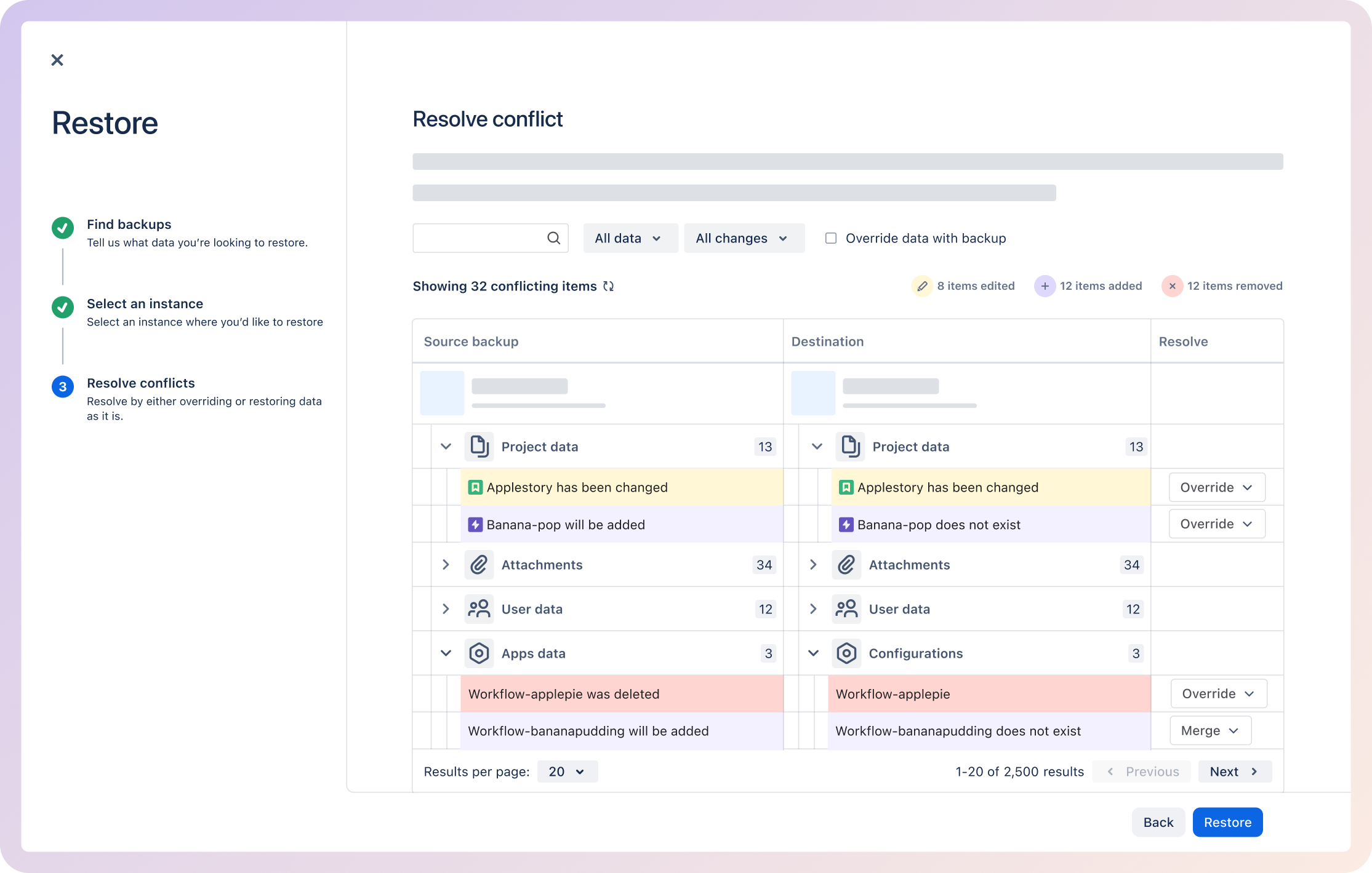
Restore conflicts & delta behavior
Restores overwrite live data, and admins previously had no visibility into conflicts or what would change.
What I solved
- Worked with architects and backend teams to define predictable conflict rules
- Explored overwrite/merge models and aligned on a scalable approach
- Designed a Restore Preview showing what will be restored, overwritten, or skipped
- Added clear warnings and conflict summaries to reduce risky restores
Impact
Made high-risk restore operations transparent and predictable, reducing restore errors, support escalations, and admin anxiety.
Research → Insights → Roadmap influence
To understand admin needs and failure patterns, I synthesized insights from interviews, survey data, SEQ evaluations and support tickets. The multiple research studies directly shaped the storage architecture, IA, backup lifecycle, and restore model thereby driving the multi-year roadmap.
Top insights
01
Low visibility = Low confidence
Admins couldn’t see the job progress or verify outcomes, leading to uncertainty about backup success & system reliability.
trust issue
02
UNCLEAR SCHEDULING
Ambiguous timing and retention policies led to configuration errors and mistrust in the backup system's behavior.
reliability risk
03
Anxiety during restore
No conflict clarity caused fear of overwriting live data, making admins hesitant to perform critical restore operations.
adoption blocker
04
Storage Control Needed
Enterprises wanted the ability to store backups in their own S3 buckets for compliance and data sovereignty requirements.
enterprise requirement
UX evolution
I led the end-to-end UX direction, guided the design team, and aligned PM + engineering on priorities as we evolved from an API-only solution to a scalable Out-of-box Backup & restore experience.
0 → 1 foundation (From no UI → first usable product)
- Introduced the first self-serve UI for creating and downloading backups
- Transitioned from API-only + Marketplace partner tools to a built-in admin experience
- Added basic policy creation and manual downloadable backups
- Unblocked key enterprise customers who previously relied entirely on support
- Early SEQ benchmarking revealed significant usability gaps (avg 3.4 SEQ)
1 → 2 refinement & scale (From basic UI → scalable mental model)
- Introduced a scalable policy framework with clearer mental models
- Added external storage support, retention clarity, and improved IA
- Refined scheduling, storage selection, and policy editing flows
- Designed a predictable restore preview + conflict handling model
- Evolved interaction patterns to support future features (incremental backups, advanced retention)
Measured Improvement
- SEQ improved from 3.4 → 6.2 across core tasks
- Major improvements in:
- Policy creation
- Policy editing
- Restore flows
- Reduced ambiguity and error-prone steps across backup & restore workflows